
Comprendre l'Architecture logicielle
Maîtriser la complexité plutôt que la subir
Tout projet logiciel d'une certaine envergure est confronté à la complexité — induite par des sources diverses : règles métier, interactions entre modules, performance, préoccupations transverses (sécurité, logging)...
Cette complexité est souvent subie, car on la traite au niveau du code en noyant la logique métier parmi les contraintes techniques. Le développeur doit alors composer avec tout cela à la fois : les couplages se multiplient et les responsabilités se diluent, jusqu'au point de rupture où modifier une partie du code risque à tout moment d'en casser une autre.
L'astuce consiste à en déporter une partie vers d'autres niveaux d'abstraction — c'est précisément l'un des rôles de l'architecture logicielle qui permet en quelque sorte de transformer de la complexité algorithmique en complexité architecturale.
Prenons par exemple l'injection de dépendances :
Sans conteneur, câbler une application signifie gérer soi-même l'arbre d'instanciation — qui crée quoi, dans quel ordre, avec quels paramètres... Avec un conteneur, on déclare simplement qu'une classe a besoin d'une autre ; c'est lui qui résout le reste. Le code applicatif ne voit plus qu'une dépendance injectée.
La complexité est ainsi prise en charge par les composants spécialisés permettant au développeur de se concentrer sur l'essentiel.
L'architecture logicielle fournit également un cadre structurant pour organiser le code proprement : définir clairement les responsabilités, les frontières et les interfaces de communication entre les modules.
Robert C. Martin en donne également une définition très parlante [1] :
L'objectif premier de l'architecture est en effet de soutenir tout le cycle de vie du logiciel. Une architecture adéquate rend le système facile à comprendre, facile à déployer et facile à maintenir. L'objectif est de réduire le coût du cycle de vie et de maximiser la productivité des programmeurs.
Principes fondamentaux
Cohésion
Le « Common Closure Principle » de Robert C. Martin l'exprime simplement : les composants qui changent ensemble restent ensemble. En pratique, cela signifie organiser le code par domaine fonctionnel plutôt que par type technique.
Un projet découpé en dossiers
/Services,/Helpers,/Utils... peut sembler ordonné en apparence — mais ces catégories regroupent des classes qui n'ont rien en commun si ce n'est leur type et deviennent rapidement ingérables dans les gros projets.
À l'inverse, un module centré sur un domaine précis (Paiement, Catalogue, Authentification...) regroupe ce qui va ensemble : il n'a qu'une seule raison de changer et cette raison est claire.
Minimiser les dépendances
Chaque dépendance entre modules est un point de fragilité ou de complications lors des évolutions. L'objectif est donc de les minimiser au maximum ou de les rendre explicites à travers des interfaces bien définies lorsqu'elles sont inévitables. Les dépendances cycliques — A dépend de B qui dépend de A — sont particulièrement néfastes (« Acyclic Dependencies Principle »).
L'encapsulation joue également un rôle clé : n'exposer que ce qui est nécessaire réduit mécaniquement la surface de contact entre modules, et donc les risques de couplage involontaire.
Inversion des dépendances
Parmi les principes qui structurent le plus une architecture, l'inversion des dépendances est sans doute le plus impactant : il faut dépendre d'abstractions, jamais des implémentations.
En pratique, un module métier ne doit pas dépendre directement d'une base de données, d'un service externe ou d'un framework. Il expose une interface ; c'est l'infrastructure qui l'implémente. L'intérêt est majeur : les implémentations peuvent changer à tout moment sans avoir à modifier le code métier.
Structuration en couches
L'architecture en couches est la mise en pratique directe des principes précédents. Robert C. Martin la formalise ainsi : les dépendances ne doivent traverser les frontières que dans un seul sens, c'est-à-dire du code technique vers les règles métier :
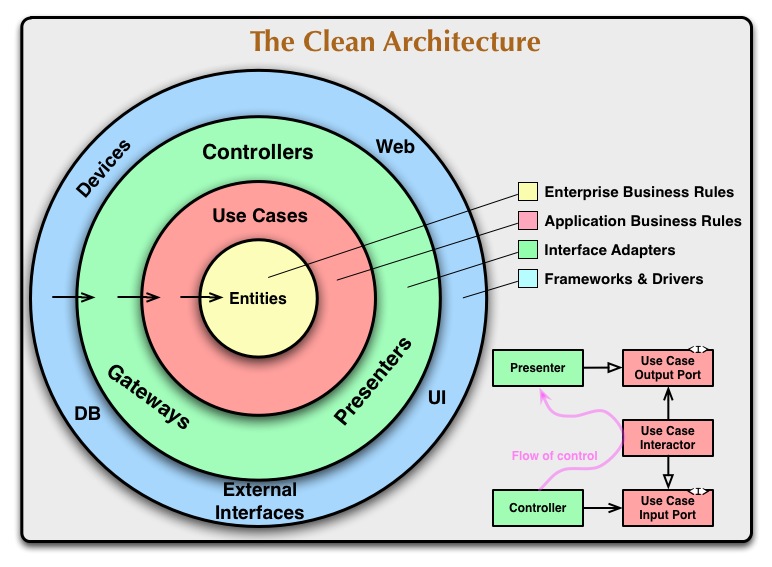
Monolithe ou microservices ?
Depuis le milieu des années 2010, les microservices ont été largement présentés comme l'architecture moderne par excellence — scalable, indépendante, déployable en continu... La réalité est plus nuancée car cette approche introduit une complexité opérationnelle considérable, souvent sous-estimée au moment du choix.
En effet, décomposer une application en dizaines de services indépendants signifie gérer autant de déploiements, de contrats d'API à versionner, de bases de données à synchroniser et la cohérence des données à assurer...
Pire encore : si les services restent fortement couplés malgré leur séparation physique, on aboutit au « monolithe distribué » [2], avec tous les inconvénients des deux approches, sans aucun des bénéfices.
Les microservices ont bien entendu leur pertinence, mais dans des contextes précis : des besoins de scaling très différenciés selon les modules ou des domaines métier clairement délimités portés par des équipes dédiées et vraiment indépendantes.
Ce n'est pas le point de départ naturel d'un projet.
Le « monolithe bien structuré » l'est bien davantage — et souvent le choix le plus rationnel, en particulier quand les frontières métier ne sont pas encore clairement établies. Martin Fowler le formule clairement dans son article Monolith First [3] : commencer par un monolithe avant d'envisager l'externalisation de certains modules permet de comprendre le domaine métier avant de tracer des frontières entre services — qui, une fois établies, sont coûteuses à remettre en question.
La règle empirique : partir monolithique et n'extraire un service que si le besoin est prouvé par l'usage — un besoin de scaling différencié, une équipe dédiée, un domaine clairement isolé... et jamais par anticipation.
Mais un monolithe n'est pas forcément synonyme de chaos architectural : structuré en modules bien délimités par domaines fonctionnels — ce qu'on appelle parfois un Modulith [4] — il peut offrir les mêmes bénéfices d'organisation qu'une architecture microservices, sans la complexité distribuée (qui répond à des problématiques très particulières).
Architecture Hexagonale et DDD
Deux approches complémentaires se sont peu à peu imposées pour structurer proprement ces monolithes « bien structurés » : l'architecture hexagonale, qui définit comment isoler le domaine de l'infrastructure et l'approche DDD (Domain Driven Design), qui place le domaine métier au cœur du projet.
Architecture Hexagonale
Proposée par Alistair Cockburn en 2005, l'architecture hexagonale — aussi appelée Ports & Adapters — applique concrètement l'inversion des dépendances à l'échelle de l'application en définissant deux zones distinctes : l'intérieur (logique métier) qui expose des ports (interfaces) et l'extérieur (base de données, interface utilisateur, API externes...) qui s'y connecte via des adapters (implémentations des interfaces).
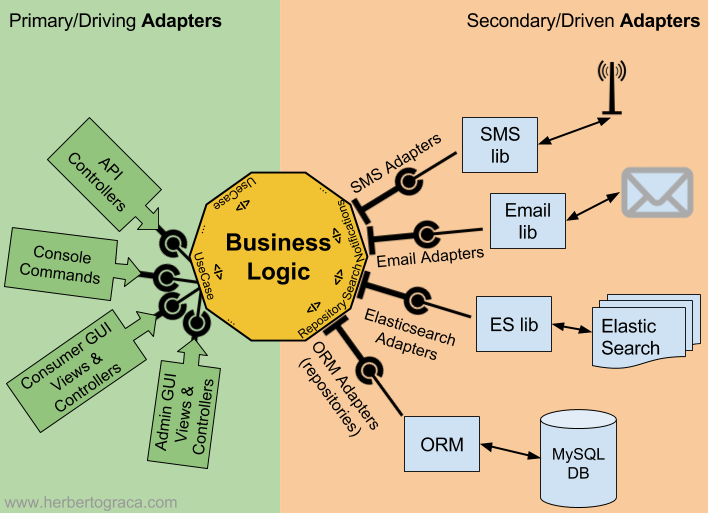
Domain-Driven Design
Le Domain-Driven Design (Eric Evans, 2003) est avant tout une philosophie de conception qui place le domaine métier au centre de toutes les décisions du projet.
Il définit en premier lieu une approche collaborative — construire un langage commun entre développeurs et experts métier, organiser les équipes autour des domaines fonctionnels — ainsi qu'un ensemble de concepts architecturaux pour traduire ce domaine fidèlement dans le code.
Comme avec l'Architecture Hexagonale — les règles métier sont isolées au centre et tout le reste en dépend, jamais l'inverse. Les interprétations varient mais conduisent toutes à une architecture en 3 ou 4 couches distinctes :
- Domaine (logique métier)
- Infrastructure (implémentation technique des interfaces)
- Application* (orchestration des cas d'usage)
- Présentation (UI, contrôleurs, commandes CLI, consumers...)
* La couche applicative est tantôt intégrée dans le Domaine, tantôt dans la Présentation, ou parfois répartie entre les deux.
Le DDD est également fréquemment associé au pattern CQRS (Command Query Responsibility Segregation), qui sépare explicitement les opérations d'écriture et de lecture.
Ces outils se combinent
L'architecture Hexagonale, Clean Architecture, DDD, CQRS ne sont pas mutuellement exclusifs — ils adressent des aspects différents et se complètent naturellement. L'article Explicit Architecture de Herberto Graça [5] montre comment les assembler efficacement en un tout cohérent.
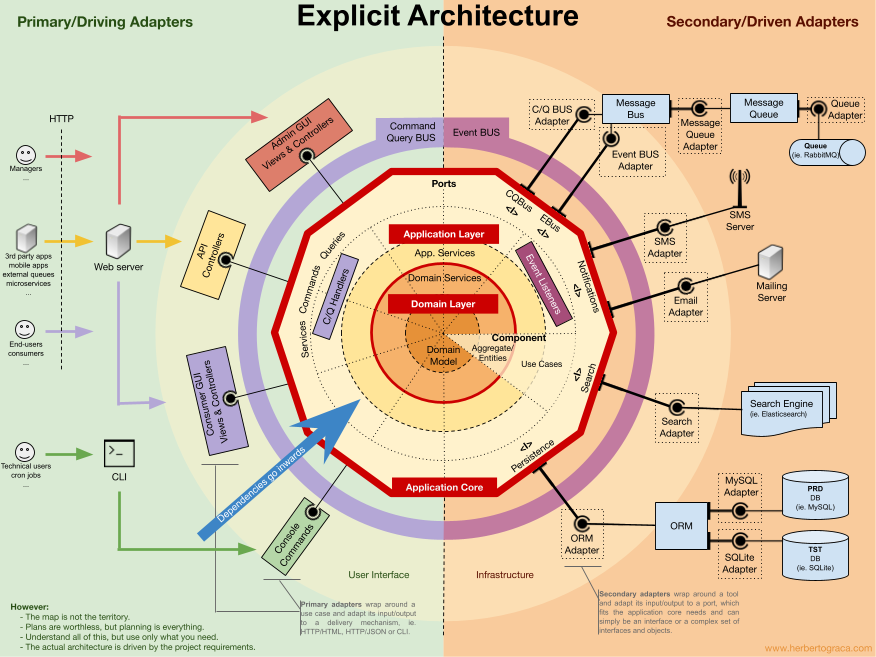
Si l'architecture logicielle est un sujet qui vous intéresse, je vous invite à lire la très instructive série d'articles The Software Architecture Chronicles de ce même auteur (2017), qui retrace l'évolution des architectures logicielles, de la programmation procédurale aux architectures modernes.
Mon expérience
J'utilise le DDD au quotidien et je le recommande pour la grande majorité des projets — y compris les plus modestes. Contrairement à ce que l'on pourrait penser, il n'ajoute pas nécessairement de complexité ou de temps de développement car c'est avant tout une manière de ranger et de nommer les choses, et porte rapidement ses fruits dès les premières évolutions du projet.
Les POCs sont probablement les seules exceptions, étant donné leur durée de vie et leur portée volontairement limitées.
Il ne faut pas être dogmatique avec les règles que le DDD propose, ce ne sont pas des commandements et il faut garder en tête l'objectif principal de ces principes : faciliter la maintenance et maximiser la productivité des programmeurs.
Deux exemples concrets :
- Utiliser des Value Objects issus d'une bibliothèque externe — les intégrer dans le Domaine semble enfreindre la règle d'indépendance. Mais en pratique, le coût de leur remplacement éventuel reste minime (copier la classe, l'adapter, faire un find/replace global du FQCN) en comparaison du coût de développer et de maintenir inutilement des classes supplémentaires.
- Intégrer le mapping Doctrine directement dans les Entités — la règle voudrait qu'il soit déporté du Domaine vers l'Infrastructure (XML, YAML). Mais à l'usage, maintenir un fichier de mapping en cohérence avec son entité est lourd et source d'erreurs. Les attributs PHP directement sur l'entité sont donc un compromis que j'assume pleinement, étant donné leur coût de remplacement également marginal.
Références
-
[1]
📔 Robert C. Martin — Clean Architecture (2017) — le livre de référence sur les principes d'architecture logicielle propre et maintenable

- [2] Mehmet Ozkaya — Microservices Antipattern: The Distributed Monolith (2024) — causes et conséquences de l'anti-pattern, avec une alternative : le monolithe modulaire
- [3] Martin Fowler — Monolith First (2015) — pourquoi commencer par un monolithe avant d'envisager des microservices
- [4] David Heinemeier Hansson — The Majestic Monolith (2016) — plaidoyer pour le monolithe « bien structuré »
- [5] Herberto Graça — Explicit Architecture (2017) — comment assembler DDD, Architecture Hexagonale, Clean Architecture et CQRS en un tout cohérent
Pour aller plus loin
- 📔 Eric Evans — Domain-Driven Design (2003) — l'ouvrage fondateur du DDD qui a posé les bases de la conception centrée sur le domaine métier
- 📔 Sam Newman — Monolith to Microservices (2019) — migrer progressivement un monolithe vers des microservices, en passant par le monolithe modulaire
- 📔 Martin Fowler — Patterns of Enterprise Application Architecture (2002) — un catalogue de patterns d'architecture pour les applications d'entreprise, dont bon nombre sont devenus aujourd'hui des standards : Repository, Data Mapper, Service Layer...